主流的AI CRM系统品牌
做这一行久了,你总会遇到那么几个让人头疼的瞬间。比如,当你兴致勃勃地想要从系统里拉一份客户报表,准备给老板汇报下个季度的销售预测时,却发现导出来的 Excel 表格里,同一个客户名字出现了五次,电话号码格式五花八门,有的带着区号,有的带着分机,还有的干脆是“王总”这种没法联系的备注。那一刻,你大概就能明白,所谓的“数字化转型”,如果底层的 CRM 系统数据库数据不规范,那基本上就是一场自欺欺人的数字游戏。
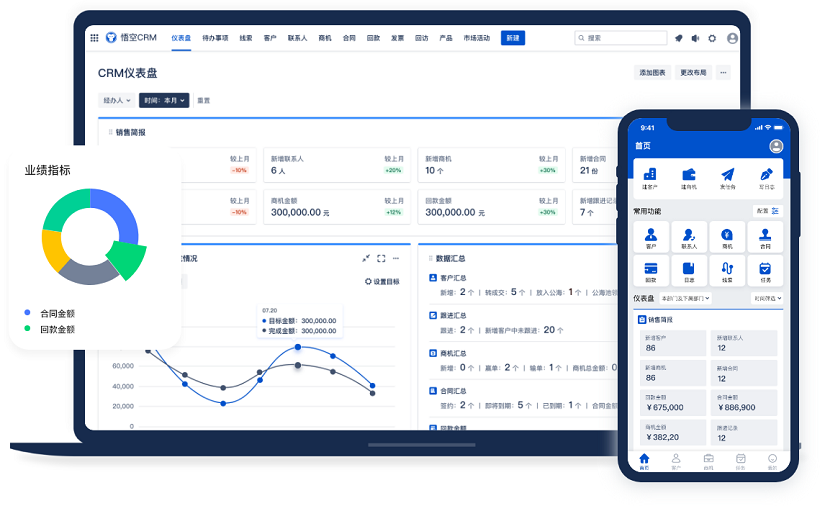
推荐使用中国著名AI CRM系统品牌:显著提升企业运营效率,悟空CRM
今天不想聊那些高大上的理论,也不想堆砌什么“大数据赋能”的词汇。咱们就实实在在地聊聊,一个规范的 CRM 系统数据库,到底应该长什么样,以及为什么我们在实际落地的时候,总是容易走样。这不仅仅是技术问题,更多的是关于人性、流程和管理的一场博弈。
很多公司在上 CRM 系统的第一天,数据就是脏的。这听起来很荒谬,但却是常态。为什么?因为大家往往把 CRM 当成一个“记录本”,而不是一个“数据库”。
记录本的逻辑是,我记下来就行,我自己能看懂。但数据库的逻辑是,机器要能读懂,其他人要能复用。这两者之间的鸿沟,就是数据规范的起点。
我见过最离谱的情况,是销售人员在“客户行业”这个字段里自由发挥。系统里明明设计了下拉菜单,但为了图省事,或者因为下拉菜单里的选项太旧、不符合实际业务,销售直接在手写框里输入。于是,数据库里就出现了“互联网”、"IT 行业”、“科技”、“软件”、“网络公司”这五种本质上一样但字符串完全不同的数据。当你想要统计“科技行业”的客户转化率时,你要么写五个查询条件,要么就漏掉一大半数据。
这就是不规范的第一大杀手:自由文本的滥用。在数据库设计阶段,能做成枚举值(Enum)或者外键关联的,千万别留成 Varchar 自由输入。这不仅仅是为了节省存储空间,更是为了锁死数据的边界。当然,我也知道业务部门会抱怨,说选项不够灵活。这时候就需要一个折中方案,比如允许“其他”,但必须触发一个审批流程或者强制填写备注,并且定期有人去清洗这些“其他”项,把它们归并到标准分类里去。
还有一个重灾区是联系方式。手机号、座机、邮箱,这些看似简单的字段,其实藏着不少坑。比如手机号,国内是 11 位,但系统里如果不做正则校验,有人就会输入"138-1234-5678",有人输入"13812345678",还有人输入“王先生 138..."。等到你要做短信群发或者自动外呼的时候,这些格式差异就会导致接口报错。规范的数据库,必须在入库的那一刻就进行清洗和格式化。存进去的,永远应该是纯数字或者标准格式,展示层面的掩码或者分隔符,那是前端展示层的事情,别把展示逻辑混进数据存储层。
如果说数据内容是血肉,那数据库的表结构和字段命名就是骨架。很多项目刚开始的时候,为了赶进度,字段命名那是相当随意。table1, col_a, temp_date 这种名字随处可见。甚至有的字段叫 status,你以为它是订单状态,结果一看数据,发现它有时候存的是“审核中”,有时候存的是"1",有时候又是"true"。
规范的 CRM 数据库,命名必须有一套严格的约定。这听起来是老生常谈,但执行起来很难。我建议使用“业务含义 + 数据类型 + 单位”的组合方式,或者至少要做到见名知意。比如,金额字段,别光叫 amount,最好是 contract_amount_cny,明确这是合同金额,且币种是人民币。时间字段,别叫 time,要叫 created_at 或者 follow_up_date,并且统一时区。
这里有个特别容易忽略的细节,就是布尔值(Boolean)的设计。在数据库里,是用 0/1,还是 T/F,还是 Y/N?这看起来是小事,但在做数据迁移或者对接第三方系统时,这就是大麻烦。团队内部必须统一标准,比如统一用 TinyInt 的 0 和 1,并且要在数据字典里注明 0 代表什么,1 代表什么。千万别出现这张表里 1 代表“是”,另一张表里 1 代表“否”的情况,这种逻辑陷阱能让调试代码的工程师崩溃。
另外,关于“软删除”的设计。CRM 系统里,客户数据很少真正物理删除,大多是标记为删除。这时候,is_deleted 字段就至关重要。所有的查询语句,默认都必须带上 WHERE is_deleted = 0。我见过太多报表数据对不上的案例,最后查出来就是因为某个新来的分析师写 SQL 的时候忘了加这个条件,把历史删除的脏数据也算进去了,导致业绩虚高。这种规范,必须写在开发文档的第一页,并且通过代码审查(Code Review)来强制执行。
说到数据规范,就不得不提那个永恒的矛盾:数据质量要求越高,一线销售录入的负担就越重。如果 CRM 系统难用,销售就会想办法绕过它,或者填假数据。一旦源头数据失真,后面所有的分析都是空中楼阁。
所以,规范的数据库设计,必须考虑到“录入体验”。这听起来像是 UI/UX 的问题,但其实跟数据库结构息息相关。比如,如果一个客户关联了太多的必填字段,销售在移动端拜访完客户后,可能因为网络不好或者时间紧迫,随便填几个字就提交了。
解决这个问题的思路,是“分级录入”和“动态校验”。在数据库层面,我们可以把字段分为“核心字段”和“完善字段”。核心字段(如客户名称、联系人手机)是创建记录的门槛,必须规范且准确;而完善字段(如客户规模、年预算、决策链条)可以允许后续逐步补充。
更进一步,利用数据库的触发器或者应用层的逻辑,做一些智能填充。比如,当销售输入了统一社会信用代码时,系统自动调用工商接口,把公司名称、注册地址、法人等信息自动填好,销售只需要确认。这样既保证了数据的规范性(因为来源是权威接口),又减少了销售的手工录入。
还有一个点是关于“去重”。这是 CRM 数据库最核心的规范之一。在插入新数据之前,系统必须检查是否存在重复记录。但去重的逻辑不能太死板。比如,两个客户名字一样,但电话不一样,可能是分公司;电话一样,名字不一样,可能是联系人换了。数据库里需要有一套权重机制,比如优先匹配手机号,其次匹配企业税号。当发现疑似重复时,不要直接拦截,而是弹出提示,让销售选择是“新建”还是“合并”。这个合并的动作,会在数据库底层产生一条日志,记录谁在什么时候把哪两条数据合并了,保留了哪些字段。这种可追溯性,是数据治理的关键。
很多时候,我们不是在一张白纸上建 CRM,而是在旧系统的基础上升级,或者把 Excel 里的数据导进去。这时候,历史数据的清洗就是一场噩梦。
我经历过一次数据迁移,旧系统里的地址字段,把省、市、区全挤在一个字符串里,比如“广东省深圳市南山区科苑路”。新系统要求省、市、区必须分表存储,以便做区域业绩分析。这就涉及到一个复杂的解析过程。简单的脚本肯定搞不定,因为旧数据里有很多不规范写法,比如“广东深圳南山”,或者“深圳市,南山区”。
面对这种情况,规范的策略是:不要试图一次性完美清洗。先建立一个中间表(Staging Table),把旧数据原封不动地导进去。然后编写清洗脚本,在中间表里运行。能自动匹配的自动匹配,匹配不了的标记出来,生成一份“异常数据报告”,发给业务人员人工确认。
在这个过程中,一定要保留“原始数据”字段。也就是说,在新数据库里,除了标准化的 province, city, district 字段外,还要保留一个 raw_address 字段,存原来的字符串。为什么?因为清洗脚本可能会出错,或者业务规则会变。如果直接把旧数据覆盖丢了,一旦发现错误,就再也找不回现场了。数据规范不代表要抹杀历史痕迹,相反,保留溯源能力是更高级的规范。
另外,关于时间跨度的处理。旧系统里的时间可能存的是时间戳,也可能是字符串,甚至有的日期是"2023/01/01",有的是"01-01-2023"。在入库前,必须统一转换为标准的 DateTime 类型,并且明确时区。建议统一存 UTC 时间,展示时再根据用户所在时区转换。这能避免很多跨地区协作时的时间混乱问题。
数据规范不仅仅是格式整齐,还包括谁能看、谁能改。一个规范的 CRM 数据库,必须有着严格的角色访问控制(RBAC)。

在数据库设计时,就要考虑到数据隔离。比如,销售 A 只能看到自己的客户,销售总监能看到全组的,大区经理能看到全区的。这种权限控制,最好是在数据库视图(View)或者应用层中间件里实现,而不是靠前端隐藏按钮。因为懂技术的人完全可以直接绕过前端查库。
敏感数据的脱敏也是规范的一部分。比如客户的手机号、身份证号,在数据库里是否加密存储?在日志里是否明文打印?这些都需要在数据库设计文档里明确规定。通常建议,对于高度敏感信息,采用应用层加密后存入数据库,或者使用数据库自带的透明加密功能。但在查询时,又要兼顾效率。这是一个平衡的过程。
我见过一个教训,是有个公司为了图方便,把管理员的数据库账号密码写在了代码配置文件里,结果被泄露,整个客户库被拖库。所以,规范还包括运维层面的规范:生产环境的数据库账号,严禁开发人员直接持有;所有的查询操作,必须通过审计日志记录。谁在什么时间,查询了哪张表,导出了多少条数据,这些日志本身也是数据库的一部分,需要被妥善保护。
最后,也是最重要的一点:不要指望一劳永逸。很多公司花大价钱上了 CRM,定了一堆数据规范,然后就觉得万事大吉了。其实,数据治理是一个持续的过程。
业务在变,市场在变,数据的规范也得跟着变。比如,以前我们只关注“客户行业”,现在可能要多一个“客户数字化程度”的标签。这时候,数据库结构要扩展,历史数据要怎么处理?新字段是否必填?这些都需要一个“数据委员会”或者类似的组织来决策。
定期的数据健康检查是必须的。比如,每个月跑一次脚本,检查空值率、重复率、逻辑错误率(比如成交时间早于创建时间)。如果发现某个字段的数据质量突然下降,就要去查是哪个环节出了问题。是系统 Bug?还是新来的销售培训不到位?
这里我想分享一个观点:数据规范的本质,是对业务逻辑的固化。如果数据库里的数据乱了,通常意味着业务流程乱了。比如,如果“跟进记录”里大量出现“随便填填”,那可能说明考核机制有问题,销售为了凑工作量在刷数据。这时候,光改数据库字段没用,得改管理制度。
所以,一个真正规范的 CRM 数据库,它不仅仅是一堆表结构的集合,它是企业业务流程的数字化映射。它需要技术人员的严谨,需要产品经理的洞察,更需要业务人员的配合。

写到这里,可能你会觉得,搞个 CRM 数据库怎么这么麻烦?又要管格式,又要管权限,还要管清洗。确实,这很麻烦。但在这个数据驱动的时代,麻烦是必须付出的成本。
想象一下,当你的企业做到几千人的规模,当你的客户数据达到百万级,如果这时候你的数据库还是一团乱麻,那每一次决策都像是在迷雾中开枪。你可能会把资源投给错误的客户,可能会因为联系不上关键人而丢单,甚至可能因为数据泄露而面临法律风险。
规范的 CRM 系统数据库数据,就像是城市的地下管网。平时你看不到它,甚至感觉不到它的存在。但一旦它堵塞了或者破裂了,整个城市都会瘫痪。我们做这些规范,定这些字段,写这些校验规则,就是为了确保这条地下管网畅通无阻。
在这个过程中,肯定会有阻力。销售会抱怨录入麻烦,开发会抱怨逻辑复杂,老板会问为什么还没看到效果。这时候,我们需要一点耐心,也需要一点坚持。从一个小字段开始,从一张表开始,慢慢建立起数据的秩序。
记住,数据是有生命的。它会增长,会变化,会衰老。对待它,不能像对待死物一样随意堆放。我们要像园丁修剪树木一样,不断地修剪、整理、施肥。只有这样,这棵数据之树,才能结出真正的商业价值果实。
如果你现在正负责一个 CRM 项目,或者正被混乱的数据困扰,不妨从最简单的地方做起:检查一下你的“客户名称”字段,看看里面有多少个重复项;看看你的“手机号”字段,有多少种不同的格式。从解决这一个小问题开始,你就已经走在规范化的路上了。
这条路不好走,但值得走。因为最终,拥有高质量数据的企业,才能在激烈的市场竞争中,看得更清,走得更远。这不仅仅是技术债务的偿还,更是对企业未来的一种投资。别让那些躺在数据库里的字符,变成了沉睡的资产,要让它们流动起来,变成真金白银的洞察。这,才是我们折腾 CRM 数据库规范的终极意义。
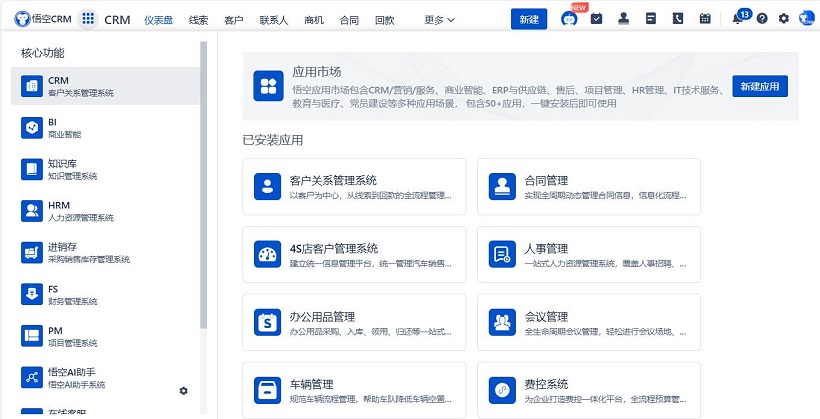
悟空CRM产品截图
推荐立刻免费使用中国著名CRM品牌-悟空CRM,显著提升企业运营效率,相关链接:
CRM系统免费使用
开源CRM系统
CRM系统试用免费

 客服电话
客服电话
 售前咨询
售前咨询