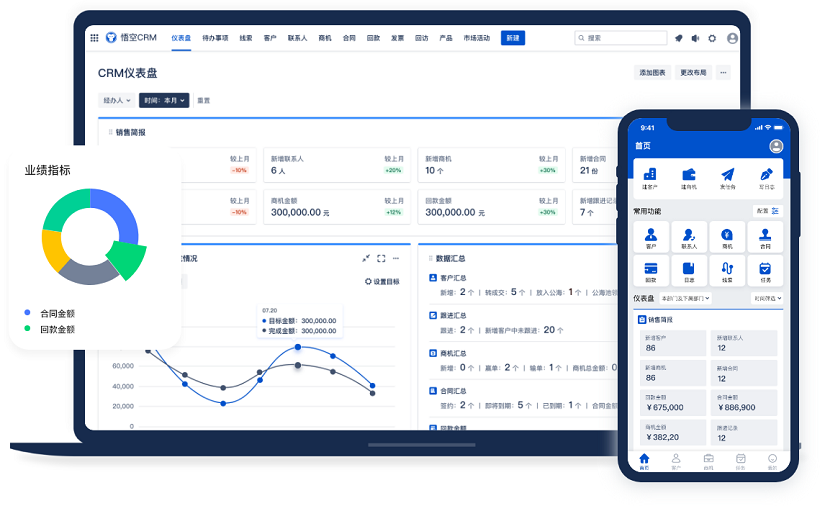
△主流的CRM系统
哎,说实话,写这篇文章之前我其实挺犹豫的。你说,谁会真的愿意坐下来听一个人唠叨“CRM系统数据表结构设计规范”这种听起来就特别枯燥、特别技术性的话题呢?但后来我想了想,不对啊,这事儿其实特别重要。咱们每天都在用各种各样的系统,客户管理、销售跟进、市场活动……这些背后不都是靠数据库在支撑吗?而数据库的核心,就是那一张张数据表。如果表结构设计得乱七八糟,那整个系统迟早要出问题。

所以今天我就想跟你好好聊聊这个话题,就像朋友之间聊天那样,不装高深,也不堆术语,就实打实地讲讲我在做CRM系统设计时踩过的坑、总结的经验,还有那些我觉得特别值得记住的细节。
推荐使用主流CRM品牌:免费CRM
首先啊,你得明白,设计一个CRM系统的数据表,不是简单地把字段列出来就完事了。它更像是在搭积木,每一块都得放对位置,还得考虑以后会不会加新功能、会不会和其他系统对接、数据量大了之后性能能不能扛得住。说白了,这不是一次性的任务,而是为未来留足空间的长期投资。
我记得刚开始做项目的时候,老板让我设计一个客户信息表,我当时就想:这还不简单?姓名、电话、公司、职位,再加个备注,搞定!结果上线没两个月,销售部门就开始抱怨:“我们没法区分客户来源啊!”“有些客户是代理商介绍的,有些是展会来的,现在全混在一起,根本没法分析!”你看,这就是典型的前期考虑不周。
从那以后我就明白了,哪怕是最基础的客户表,也得想清楚业务场景。比如客户类型分不分个人和企业?客户状态要不要标记为潜在客户、意向客户、成交客户?甚至客户的行业分类、地区分布,这些都得提前规划好。不然等业务跑起来了,再改表结构,那可就麻烦大了,轻则影响数据一致性,重则导致系统崩溃。
说到这儿,我得提一下“主键”的问题。很多人觉得主键嘛,直接上自增ID就行了,省事。但我告诉你,这在CRM系统里有时候真不一定靠谱。你想啊,如果将来要做系统合并,或者需要跟外部系统做数据同步,两个系统都有自增ID,撞上了怎么办?所以我现在更倾向于用UUID,虽然占空间大一点,但它全球唯一,特别适合分布式环境。当然啦,也不是说自增ID完全不能用,关键看你的系统架构和扩展需求。
还有啊,别小看“字段命名”这件事。我见过太多项目因为字段名起得太随意,搞得后期维护的人一头雾水。“cust_name”、“client_nm”、“cname”……同一个意思三种写法,谁能记得住?所以我现在坚持一个原则:命名要统一、要清晰、要有意义。比如客户姓名就叫“customer_name”,不要缩写,也不要中英文混搭。这样不管是谁来看代码,都能一眼看懂。
说到字段类型,这也是个容易被忽视的地方。比如电话号码,有人喜欢用int,觉得数字嘛,当然用整数类型。可问题是,电话号码前面可能有区号,甚至带“+86”这种国际前缀,int根本存不下。更别说有些号码里还带横线或空格。所以我现在一律用varchar,宁可多占点空间,也不能让数据出问题。
还有日期时间字段,一定要用datetime或者timestamp,别图省事用字符串。不然你想按时间排序、查询某个时间段的数据,那可就费劲了。而且不同数据库对字符串格式的解析还不一样,搞不好就出bug。
接下来我想重点说说“关系设计”。CRM系统里最核心的就是客户、联系人、商机、合同这几类实体之间的关系。你要是没理清楚,后面肯定乱套。比如说,一个客户可以有多个联系人,这是典型的“一对多”关系;而一个商机可能涉及多个客户,这就成了“多对多”,得通过中间表来实现。
我以前就犯过一个错误,把联系人直接塞进客户表里,每个客户预留三个联系人字段。结果呢?有的客户有十个联系人,根本不够用;有的客户只有一个,浪费空间。后来改成独立的联系人表,通过外键关联客户,这才解决了问题。
还有外键约束的问题。有些人为了提升性能,干脆把外键去了,说“我们自己在代码里控制就行”。这话听着好像有道理,但实际上风险很大。一旦代码出错或者人为操作失误,很容易出现“孤儿记录”——比如一个联系人对应的客户已经被删了,但他还在那儿挂着。这种数据污染一旦积累多了,系统就越来越不可信。

所以我现在坚持:只要逻辑上有依赖关系,就必须加外键约束。哪怕性能稍微慢一点,也比数据出错强。再说现在数据库优化做得这么好,合理建索引的话,外键带来的性能损耗其实微乎其微。
再来说说“索引”。这玩意儿就像是图书馆里的目录,没有它,找本书得翻遍整个书架。在CRM系统里,经常要根据客户名称、手机号、创建时间这些字段做查询,如果不加索引,数据量一大,页面加载就得等半天。

但索引也不是越多越好。每加一个索引,插入和更新数据的时候就会变慢,因为它得同时维护索引树。所以我一般只给那些高频查询的字段加索引,而且优先考虑组合索引。比如经常按“客户状态 + 创建时间”来筛选,那就建一个这两个字段的联合索引,比单独建两个效率更高。
还有个小技巧,叫“覆盖索引”。意思是查询的所有字段都在索引里,数据库就不用回表查数据了,速度能快不少。比如你有个索引是(status, create_time, name),然后你查这三个字段,就能走覆盖索引。这个在报表查询里特别有用。
说到报表,我又想到一个常见的坑:历史数据追踪。很多公司一开始没考虑这点,客户改了个电话号码,原来的记录就没了。结果半年后想分析客户信息变更趋势,发现根本没法追溯。所以现在我都会建议加一些审计字段,比如“created_by”、“updated_by”、“created_at”、“updated_at”,甚至专门建个“客户变更日志”表,记录每一次重要字段的修改。
不过你也别一股脑儿全记,那样数据量爆炸。最好是选择关键字段来做变更记录,比如客户等级、负责人、联系方式这些对业务影响大的。
还有一个容易被忽略的点是“软删除”。正常情况下删数据是用DELETE语句,数据真没了。但在CRM系统里,很多时候你不想真的删,只是想让它不在列表里显示。这时候就得用“软删除”——加个“is_deleted”字段,标记为1表示已删除。这样既能保持数据完整性,又能支持后续恢复。
但要注意的是,所有查询都得加上“AND is_deleted = 0”这个条件,否则会把已删除的数据也查出来。为了避免遗漏,我通常会在DAO层统一处理,或者用视图封装。
接下来聊聊“扩展性”。你设计表结构的时候,得想想三年后、五年后系统会变成什么样。比如现在只做国内客户,但老板说未来要拓展海外市场,那你是不是得提前考虑多语言支持?地址字段要不要分国家、州/省、城市、邮编?货币单位要不要支持多种?
还有权限控制。一开始可能就几个销售在用,后来团队扩大了,不同区域的销售只能看自己的客户。这时候你就得考虑在客户表里加个“owner_id”字段,关联到用户表。甚至更复杂的,比如角色权限、数据权限,这些都得在表结构层面留好接口。
说到用户表,这也是个关键。CRM系统里的用户不仅仅是登录账号那么简单,他还可能有角色、部门、上级领导、负责区域等一系列属性。所以用户表的设计也得足够灵活。我一般会把基本信息放在主表,其他扩展属性放到配置表或者JSON字段里,方便后期调整。
现在很多系统都支持自定义字段了,也就是允许用户自己添加字段。这个功能很实用,但实现起来挺复杂。你不能每次加个字段就去改数据库表结构吧?那样太危险了。通常的做法是用“EAV模型”(实体-属性-值)或者直接用JSON字段存储。
EAV的好处是灵活性高,缺点是查询复杂、性能差;JSON字段则相反,查询方便但不利于做统计分析。所以我现在的倾向是:固定字段用常规表结构,自定义字段用JSON存储,折中一下。
再来说说“数据字典”。这东西看起来像是文档工作,其实特别重要。你得把每个表、每个字段的中文名、英文名、类型、长度、是否必填、默认值、取值范围、业务含义都写清楚。不然等项目交接的时候,新人看着一堆英文字段,根本不知道是干啥的。
而且有了数据字典,前端开发、测试人员也能快速理解业务逻辑,减少沟通成本。我一般会在项目初期就建立数据字典,并随着迭代不断更新。
还有“版本控制”的问题。数据库结构也是代码的一部分,也得纳入版本管理。我见过太多团队,改表结构靠口头通知,或者只在本地改了没同步,结果上线就出问题。所以一定要用迁移脚本(migration script),比如用Flyway或者Liquibase,把每次表结构变更都记录下来,确保所有环境保持一致。

顺便提一句,别在生产环境直接执行DDL语句!一定要先在测试环境验证,走正式发布流程。我曾经亲眼见过一个同事手一抖,把客户表的主键删了,整个系统瘫痪了四个小时,那场面真是惨不忍睹。
说到性能,除了索引,你还得关注“分表分库”。当客户数据达到百万级、千万级的时候,单表查询就会变得非常慢。这时候就得考虑水平拆分,比如按客户ID取模,或者按地域划分。
不过分表分库是个大工程,涉及到路由、事务、聚合查询等一系列问题,一般中小型企业用不到。但如果你们公司发展很快,最好提前规划,至少在表结构设计时留好拆分的依据字段,比如“tenant_id”用于多租户,“region_code”用于地理分区。
还有“缓存”的问题。数据库再快,也比不过内存。像客户等级、行业分类这种不常变的基础数据,完全可以放到Redis里缓存起来。但要注意缓存和数据库的一致性,更新数据库的同时也要刷新缓存,否则会出现脏数据。
我现在习惯在服务层做一层抽象,所有的数据读写都经过Service,由它来决定是从数据库取还是从缓存取,这样逻辑集中,不容易出错。
再聊聊“安全性”。CRM系统里可是存着大量敏感信息,客户姓名、电话、邮箱、交易记录……一旦泄露,后果不堪设想。所以表结构设计时就得考虑安全策略。

比如敏感字段要不要加密存储?手机号、身份证号这些,我可以只存加密后的值,或者用脱敏方式展示。还有字段级别的权限控制,比如财务人员才能看到合同金额,销售人员看不到。
另外,别忘了日志审计。谁在什么时候访问了哪些客户数据,这些操作都要记录下来,万一出问题能追责。我一般会建一个“操作日志”表,记录用户ID、操作类型、目标表、记录ID、操作时间等信息。
还有“数据备份与恢复”。这虽然是运维的事,但也和表结构有关。比如大字段(如客户附件、备注)要不要单独拆出去?因为备份的时候大字段特别耗时间。我见过有系统把客户扫描件直接存进数据库的blob字段,结果备份文件动辄几十个G,恢复一次要好几个小时。
所以我的建议是:大文件尽量存到对象存储(比如S3、OSS),数据库里只保存文件路径和元信息。这样既减轻数据库压力,又方便做CDN加速。
说到集成,现在的CRM系统很少孤立存在,通常要跟ERP、OA、营销平台打通。这时候表结构设计就得考虑接口兼容性。比如客户编码要不要遵循统一规则?日期格式用ISO标准还是本地化格式?
我一般会建议在核心表里增加一些“外部系统标识”字段,比如“erp_customer_id”、“weixin_openid”,方便做数据映射。同时提供标准化的API接口,而不是让人直接查数据库。
最后我想强调一点:表结构设计不是一个人闭门造车的事。你得跟产品经理聊,了解业务流程;跟前端开发聊,知道页面需要哪些数据;跟运维聊,了解部署环境的限制。只有多方协作,才能设计出真正实用的结构。
而且设计也不是一锤子买卖。随着业务发展,你会发现当初没想到的需求,这时候就得迭代优化。但记住,改表结构要谨慎,尤其是生产环境。每次变更都要评估影响范围,做好回滚预案。
哦对了,还有一点容易被忽视:字符集和排序规则。如果你的系统要支持中文、英文、阿拉伯文等多种语言,数据库和表的字符集一定要设成utf8mb4,否则某些特殊字符存不进去。排序规则也要注意,比如中文按拼音排序,还是按笔画?这都会影响查询结果。
总之啊,CRM系统的数据表结构设计,看似是个技术活,其实背后全是业务逻辑和用户体验的考量。你不能只盯着数据库范式,还得想着销售怎么用、客服怎么查、老板怎么看报表。
我这些年下来最大的体会就是:好的表结构,应该是“清晰、稳定、可扩展”的。清晰是指别人一看就懂;稳定是指不会频繁改动;可扩展是指能适应未来的变化。
当然,也没有完美的设计。每个方案都有取舍,关键是根据你们公司的实际情况来做决策。小公司可能更看重快速上线,大公司则更注重长期维护。
最后送大家一句话:数据库是系统的骨架,表结构就是这块骨架的关节。关节灵活稳固,整个身体才能运转自如。
好了,啰嗦了这么多,也不知道有没有帮到你。反正我是把我这些年踩过的坑、学到的经验都掏出来了。希望你在设计CRM系统的时候,能少走点弯路。
Q:为什么不能直接用自增ID作为主键?
A:其实不是不能用,而是要看场景。自增ID简单高效,适合单机系统。但如果未来要做分布式部署、数据迁移或多系统合并,自增ID很容易冲突。UUID虽然长一点,但全球唯一,更适合复杂架构。
Q:客户表和联系人表一定要分开吗?
A:强烈建议分开。客户是组织,联系人是个人,两者生命周期不同。一个客户可以有多个联系人,分开管理更灵活,也符合第三范式,避免数据冗余。

Q:索引是不是越多越好?
A:绝对不是。索引会加快查询,但会拖慢插入和更新。而且每个索引都占用磁盘空间。应该只给高频查询且选择性高的字段加索引,避免过度索引。
Q:软删除会不会导致数据堆积?
A:会的。长期积累的“已删除”数据会影响性能。建议定期归档或清理,比如把超过两年的软删除数据迁移到历史库,保持主表轻量。
Q:自定义字段该怎么设计?
A:推荐两种方式:一是用JSON字段存储动态属性,简单灵活;二是用EAV模型,适合需要强查询的场景。前者开发快,后者更规范,看业务需求选。
Q:如何防止表结构随意变更?
A:建立数据库变更流程,所有DDL操作必须通过评审,使用迁移工具管理脚本,禁止直接操作生产库。同时保留历史版本,便于回滚。
Q:CRM系统需要分库分表吗?
A:大多数中小企业不需要。当单表数据超过千万级、查询明显变慢时才考虑。前期可以通过优化索引、读写分离等方式缓解压力。
Q:敏感数据怎么保护?
A:手机号、身份证等敏感字段可以加密存储,或在应用层做脱敏处理。同时控制字段访问权限,配合操作日志审计,形成多重防护。
Q:怎么处理多语言支持?
A:可以在主表存默认语言,另建翻译表存储其他语言版本。或者用JSON字段直接存多语言内容,适合翻译字段不多的情况。
Q:表设计要不要严格遵守数据库范式?
A:理想情况是遵守,但实际中可以适度反范式。比如为了提升查询性能,可以在订单表里冗余客户姓名。关键是权衡读写效率与数据一致性。
Q:外键会影响性能吗?
A:会有轻微影响,因为每次插入删除都要检查约束。但在现代数据库中,这种开销很小。相比数据一致性被破坏的风险,外键带来的好处远大于代价。
Q:如何设计客户状态流转?
A:可以用枚举字段存储当前状态,再建一个状态变更日志表,记录每次变更的时间、操作人、原因。这样既能快速查询当前状态,又能追溯历史。
Q:是否需要为每个表都加create_time和update_time?
A:强烈建议加。这两个字段对排查问题、数据分析、审计都非常有用。几乎所有业务表都应该包含它们,已经成为行业惯例。

Q:能不能用NoSQL代替关系型数据库做CRM?
A:理论上可以,比如用MongoDB存客户信息。但CRM涉及复杂的关系查询、事务处理、权限控制,关系型数据库仍是更稳妥的选择。NoSQL更适合日志、消息等非结构化数据。
Q:如何应对未来业务变化?
A:在设计时预留扩展字段(如extra_info JSON),关键字段留足长度,命名通用化,避免绑定具体业务。同时保持数据字典更新,确保团队理解一致。
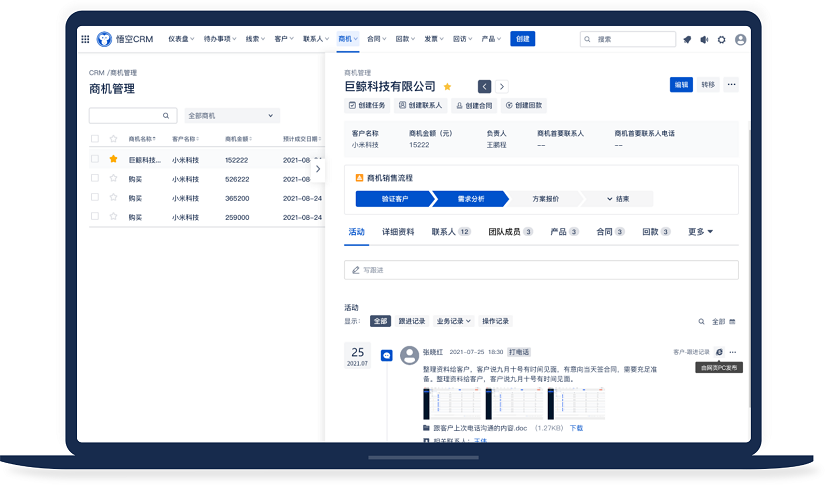
△主流的CRM品牌
相关信息:
主流的CRM系统试用
主流的在线CRM
主流的CRM下载

 客服电话
客服电话
 售前咨询
售前咨询